Profium Sense™ Graph Database
 Profium Sense™ Graph Database
Profium Sense™ Graph Database
Graph database market is expected to grow from USD 1.9 billion in 2021 to USD 5.1 billion by 2026. Applications like digital asset or logistics or collection management require flexible ways of storing relationships between objects for real-time retrieval of complex data. Unlike relational databases and graph databases built on relational databases, native graph databases like Profium Sense™ Graph Database can store complex interconnected data and enable versatile queries traversing through the data with low latency.
Profium Sense™ Graph Database is a native in-memory RDF graph database that has a patented Rule Engine optimised for real-time operations.
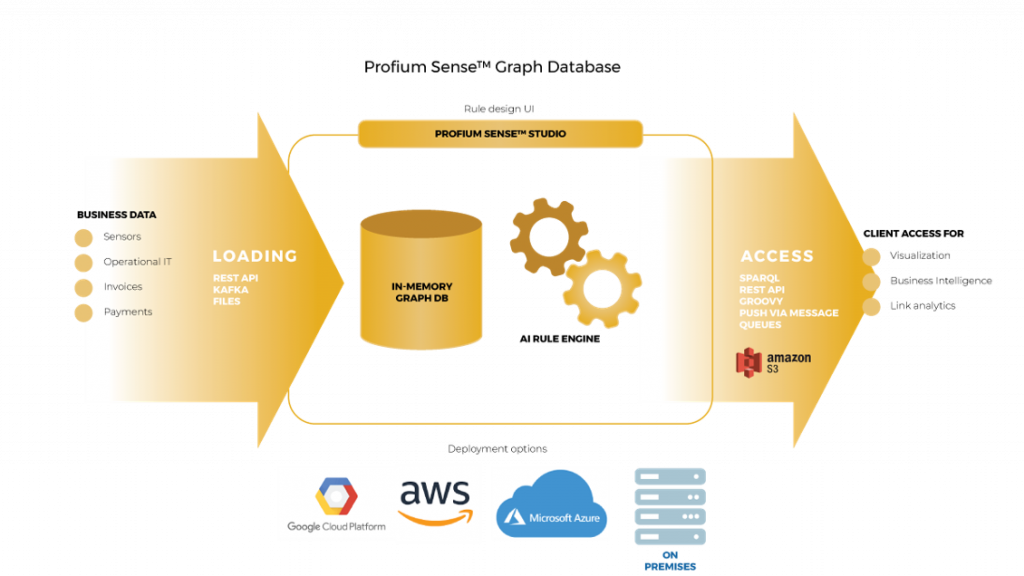
Profium Sense™ Graph Database can constantly monitor and ingest data from heterogeneous sources such as news feeds, CRM, IoT, Open and Big Data. The data is then enriched and interlinked with the help of Profium’s patented rule engine. This approach gives users real-time access to the data and allows them to make smarter decisions and perform their daily work more efficiently.
Patented Rule Engine
Profium Sense Rule Engine is a proven Artificial Intelligence (AI) engine to evaluate logical rules. It is based on a patented algorithm that is capable of inferencing over high throughput of concurrent inserts and delete operations in parallel. Profium Sense capabilities include reasoning over RDF metadata using configurable and dynamically modifiable rule sets and ontologies.
Efficient rule management with Profium Sense™ Studio
Profium Sense™ Studio is an easy-to-use graphical rule editor for defining classification rules. Using the editor user can create complex rules that can share common parts. Once the rule definition is complete, users can saves it with a click of a button to Profium Sense™ Graph Database. Profium Sense™ Studio is used by AFP and DIGITAL AND POPULATION DATA SERVICES AGENCY.
Incremental inference: no need to recalculate over large datasets
Inference takes place incrementally and the algorithm is fully bidirectional: frequent updates and rule set changes will not require complete recalculation over large datasets. This unique approach makes it ideal for gigabyte size datasets with frequent updates. Reasoning algorithm takes place as forward chaining inference where all inferred metadata is materialized during insertion time, making no performance implications to information retrieval or query processing.
RDFS, OWL and custom rules supported
Rule Engine supports custom rules as well as ontologies such as RDF Schema (RDFS) and Web Ontology Language (OWL) . Using these ontologies helps enrich your content descriptions automatically.
Expression power of custom rules include not only trivial data transformations and combinations, but also complex filtering using built-in comparison operators for numerics and dates, geographical and distance matching, text and regular expression matching and user-defined functions using JavaScript.
Lightning fast queries through in-memory architecture
Profium Sense™ Graph Database stores triples in memory, which provides for low latency queries on complex data sets. Optimised full text indexing enables efficient searches for textual content which is encoded in graph.
Product features
| Database model | RDF store |
| Current release | 8 |
| License | commercial |
| Deployment models | Cloud and on-prem |
| Implementation language | Java |
| Server operating systems | Linux (RHEL 8) |
| Data scheme | schema-free |
| Typing | Yes |
| XML support | Yes |
| Access | SPARQL, Java API, HTTP API, Groovy |
| Supported programming languages | Java |
| Triggers | Yes |
| Replication methods | HA-Cluster |
| Consistency concept | Eventual consistency |
| Transaction concepts | ACID (single node) |
| Inferencing | Forward chaining (Horn clauses) |
| Concurrency | Yes |
| Persisting data | Yes |