Graph database use cases (10 examples)
You Are Using Graph Databases Every Day!
How’s it possible that LinkedIn can show all your 1st, 2nd, and 3rd -degree connections, and the mutual contacts with your 2nd level contacts in real-time. The answer is: because LinkedIn organizes its entire contact network of 660+ million users with a graph!
Did you know that also Google’s original search ranking is based on a Graph algorithm called “Pagerank”?
Why are the recommendations on Amazon.com always so spot-on? Well, they use a graph database — and, by the way, so do many other e-commerce giants such as Wish.com.
Instagram, Twitter, Facebook, Amazon, and, practically, all applications, which must rapidly query information scattered across an exponentially-growing and highly-dynamic network of data, are already taking advantage of Graph Databases.
Why are companies moving from Relational databases to Graph technology? Read our overview of the 10 most prominent Graph Database use-cases to see the advantages!
If you want to find out how to deploy Graph Database in your case, don’t hesitate to contact us!
What’s a Graph Database?
Graph Database presents data as entities, or nodes. Nodes can have properties that have further information. Nodes are connected to other nodes with edges. Each connection between two nodes can be labeled with properties.
Here is a very simple Graph Database example:
Node A: John, Node B: ACME Inc., Node C: Austin, Edge 1: works_in, Edge 2: lives_in. This database tells you that John works in ACME Inc and he lives in Austin.
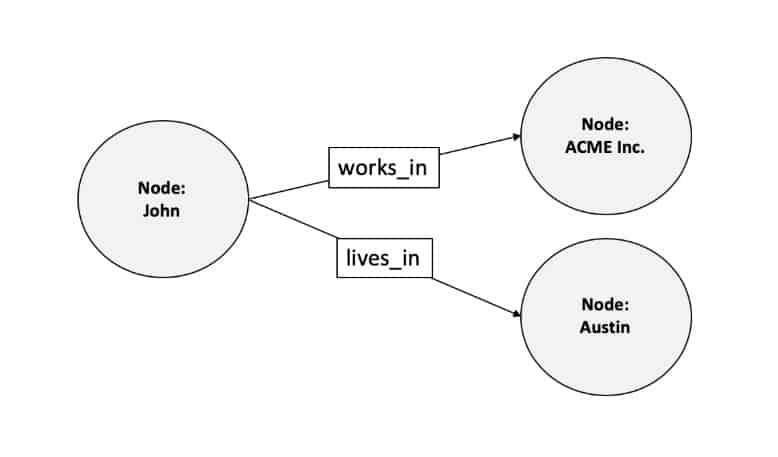
If you draw this database into a picture to illustrate the relationship between nodes A, B and C, you will end up with the above graph structure. That’s why it is called the Graph Database.
The Graph Database might not be the best option for each and every application. However, it certainly is a strong alternative in increasingly many database use-cases. Here’s a list of the ten most prominent use-cases for Graph Databases.
The Ten Most Common Graph Database Use-cases You Should Know
There is a good reason why the world’s forerunner-businesses are increasingly using Graph databases. This modern technology offers unprecedented agility, scalability, and performance for managing vast amounts of highly dynamic and exponentially growing data for various use-cases — this is precisely what today’s applications require.
And, the Graph database is adopted for ever more use-cases and applications as organizations continue implementing the Graph technology.
The Graph database reveals the complex and hidden relationships between separate data sets, allows you to analyze them, to further improve your business processes, and make smarter business decisions, faster.
Words are just words until put to practice.
All these use-cases have been successfully implemented in a real business environment — Profium has deployed most of them.
Graph Database for Recommendation Engines in E-commerce
Recommendation engines in E-commerce are a perfect use-case for Graph database. The benefits are obvious – with the Graph technology you can provide your customers with accurate recommendations and maximize your online sales and customer satisfaction.
In e-commerce, Graph-based recommendation engines are used in web shops, various types of comparison portals, and for example, in hotel and flight booking services.
How to use Graph Database in E-commerce?
Graph databases map networked objects and provide relationships between different objects. The objects are referred to as nodes, and the connections between them are edges. Typical examples of nodes in an e-commerce application include customers, products, searches, purchases, and reviews. Each node represents some piece of information in the Graph, whereas each edge represents a contextual connection between two nodes.
This enables you to retrieve relevant information about your customers, the channels they use, searches they make, and, for example, their purchase history. Based on this data, you can easily provide accurately personalized recommendations based on, both, customers’ own data, and that of the other similar users.
Both, the nodes and edges can be assigned any number of properties and the links can be queried again, e.g. the price, rating, and genre of an article, or how long a product has been on a “watch list”.
Example Graph for E-commerce
Here’s an example of how you could apply Graph in an e-commerce business selling skateboards:
“Customer” and “skateboard” are represented as nodes that are linked together by edges (e.g. “searched”, “bought”, “reviewed”).
The edge “reviewed” can be given the attribute “1 star”, “2 stars” or “3 stars”.
If you want to use this information for referrals, you can follow a customer’s connections to find other customers who have made skateboard related searches, or likes, and use this data to provide referrals.
In addition to representing known facts as nodes and edges in the graph, additional information can be inferred based on these facts.
For example if the Graph contains information that certain skateboards are meant for ramps whereas another skateboard is meant for commuting you can infer that customers who buy these skateboards are using it at ramps, by adding nodes and edges to the graph to represent this.
Inferred data enriches the graph making it easier to make connections between related things and easier to query the data by removing levels of indirection. Customizable rules define how inferred data is dynamically generated and added to, or removed from, the graph as it changes.
Benefits of Graph Database in E-commerce Recommendation Engines
Graph databases are just perfect for e-commerce applications and recommendation engines. Depending on the case, they can perform much faster than alternative systems.
You can add and link information from the browser, run search queries, click histories and social channels to user profiles to build up a rich and complete profile of your customers. The more you can accumulate clicks, searches, purchases and other events, the richer the customer profiles become. New customers, pre-marked articles, as well as comments and assessments are added and immediately considered in the next recommendation. So, the data record remains current.
Master Data Management (MDM)
Master Data Management enables you to link all your company’s critical data to one location – a.k.a. the master file – to provide a single point of reference to all data.
If your MDM is appropriately implemented, it streamlines data sharing among your personnel and departments and aggregates data located in silos, i.e., in multiple separate systems, platforms, and applications. With an excellent MDM system, the employees and applications across your organization get consistent and accurate data always.
Graph or Relational Database in MDM?
The Master Data Management system is constantly performing several functions: collecting, aggregating, matching, consolidating, and distributing data, and ensuring quality and persistence throughout your organization.
However, because master data consists of a series of connections, managing your MDM on a relational database becomes complex and slow. Besides, your master data integrate often with cross-enterprise applications, which makes real-time querying a burdening process.
Luckily there’s a better alternative for building an efficient MDM – the Graph databases are optimized for handling contextual relationships between multiple data objects. So, Graph technology offers you a much faster and more effective way to organize the master data.
Compliance with GDPR, HIPAA and Other Regulations
Companies are struggling to comply with privacy regulations such as GDPR, General Data Protection Regulation. With just one year of GDPR in effect and already 90,000 data breaches had been reported, 500 investigations were ongoing, and several companies had already been punished with fines – the highest was up to € 50 million.
And, more and more international regulations are enforced, which puts a strain on companies – especially those organizations that store sensitive customer data.
Besides GDPR in the EU, the California Consumer Privacy Act – based on GDPR – is set to go into effect at the beginning of 2020. Privacy standards in Japan, Brazil, Argentina, and many other countries have been aligned with GDPR. The American HIPAA, Health Insurance Portability and Accountability Act regulates the flow of information in healthcare and insurance.
If so many organizations fail to comply with GDPR, could the outdated database technologies be the root-cause?
Relational Databases do Not Scale for GDPR
Relational Databases are great for managing relatively static and structured data, with uniform connections between different data entities. But, that’s not what you will be up against with GDPR!
Personal data is spread across several applications on your own servers, data centers, and external cloud services. According to GDPR, you must be able to track the movement of the data that is in your possession – where did you acquire it, was consent obtained, how does it move over time, where it is located, and how it is used.
Therefore, the connections between different data entities are crucial for tracking the complex path that personal data follows across your domain. Additionally, you must be able to access, report, and remove all this data if required by consumers or authorities.
If you try to track GDPR compliance with a relational database, you will end up with a massive constellation of JOIN tables, thousands of lines of SQL code, and complex queries. Maintenance becomes a headache because you need to add more systems and data relationships. Execution of queries will drain your computing when the system grows.
The Graph is the Best Database for Regulatory Compliance Systems
Regulatory Compliance Systems are one of the most deployed use-cases for Graph Databases.
The Graph Database is optimized for connected data applications such as GDPR, where data relationships are crucial. The Graph tracks and stores contextual connections between vast amounts of heterogeneous data points, and this model, in fact, perfectly resembles the regulatory systems such as GDPR and HIPAA.
Graph systems enable single queries that can offer a visual representation of the results. In this way, they help organizations maintain compliance by tracing data throughout enterprise systems in a more organized manner than a relational database.
Symbolic AI (Symbolic Reasoning)
According to the analyst firm, Gartner, Business Intelligence, and Analytics will be based on Artificial Intelligence and Machine Learning in the future.
In Machine Learning, the algorithm learns rules based on system inputs and outputs. Symbolic Learning requires human intervention. To build a Symbolic Reasoning system, humans have to learn the rules first, and then enter those rules and relationships into a static program.
So, why is Symbolic Reasoning a use-case for Graph Databases?
Because, to create new rules, you must understand the relationships between different entities, and that isn’t very easy for humans if a visual representation of the data is not available.
The Graph Database solves this problem. It shows the data entities and how they connect and relate to each other. This visual representation allows humans to understand the data intuitively, which then makes it a lot easier to create meaningful new rules.
Graph Database Example:
The following image provides a snapshot view from a Graph Database. Just by looking at it for a few seconds, you can understand that Limerick is a city and also a county in Ireland. Additionally, you can see that Limerick is related to eight entities (nodes) in the database, and five data items define what kind of city Limerick is.
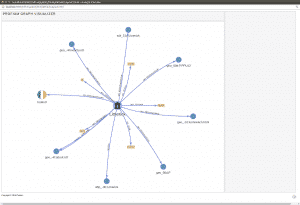
On a Graph Database, you can intuitively understand all this in a few seconds – in a Relational Database; it would take several minutes.
Digital Asset Management (DAM)
An overabundance of digital content is one of the biggest problems for most enterprises today. They are managing unprecedented amounts of documents, images, product descriptions, video material, audio files, and everything in between.
DAM systems store, organize and share all these digital assets in a central location in your company. DAM helps your teams accomplish their goals and quickly find the right files when needed. DAM unleashes the full potential of your organization – but, only if the database behind it scales up with the rapidly growing data volume, ever-diversifying content types, and delivers your employees the right files quickly.
The Graph Database provides just this — simple, scalable and cost-efficient database to track how your company’s digital assets such as documents, contracts, and reports related to the employees, who created the files and when, who are allowed to access which files, and so on. With the Graph Database model, Digital Asset Management becomes intuitive.
Graph Database Example:
Netflix uses Graph Database for its Digital Asset Management because it is a perfect way to track which movies (assets) each viewer has already watched, and which movies they are allowed to watch (access management). Note that also Identity and Access Management (IAM) has an essential role in the DAM.
Context-aware Services
Context-aware Services use information about the user’s Context – such as the location – to provide him or her with relevant services and information at the right moments.
There are countless examples of context-aware services – these include: delivering real-time traffic updates around the user’s current whereabouts, streaming a live video from the route the user has planned, sending farmers timely and relevant pest and disease observations from the nearby farms, or, alerting for high pollen exposure along children’s school way.
The same Context-aware services are also used for contextual marketing – so, delivering customers relevant information and offers based on their location or profiled interests, rather than spamming them with ads randomly.
Context can refer to real-world characteristics such as temperature, time or location. This information can be updated by the user manually, or by other mobile devices, applications or sensors.
Why use Graph Database for Context-aware services?
The basic idea in Context-aware Services is to look for past contexts similar to the user’s current Context, and use that information to make actionable decisions based on which the user is delivered relevant services or information.
Graph Database is a natural solution for implementing Context-aware Services. The Graph consists of nodes representing contexts and edges connecting the nodes.
The Graph structure enables you to retrieve related contexts similar to the current Context much faster compared to if a Relational Database was used.
Fraud Detection
Hacking has been the most common cause of data breaches in recent years. Approximately 5,000 major incidents were discovered in 2018 alone – 39% of them were carried out through the Web. As a result of online fraud, billions of sensitive data records are exposed yearly, and the economic losses account for billions of dollars.
Online fraud is extremely difficult to combat – the techniques evolve rapidly, fraud rings change constantly, and they can grow quickly.

To prevent modern, advanced fraud rings, you must be able to detect when and where these rings of false accounts emerge – it can happen suddenly, anytime, and anywhere in the world.
The rings can grow to cover thousands of nodes quickly. Analyzing these records is not yet enough. You must be able to detect how they link to other data points such as credit card records, addresses, or transactions, and analyze these highly complex data relationships.
Why Choose Graph Database for Fraud Detection?
To limit the damages of fraud, you must detect and prevent incidents as they happen, in real-time.
Conventional fraud detection techniques based on relational databases are optimized to analyze discrete data records, but they do not scale up to analyze how the records relate to each other.
Preventing advanced online fraud requires highly scalable, real-time link analysis across large interconnected data – and, that’s exactly why you should build your Fraud Prevention based on Graph databases!
base
Applying Graph Database for Fraud Detection
The Graph structure allows you to look further than just discrete data points to the connections that link them. Understanding the connections between data, and deriving meaning from these links you can reframe the problem in a different way and draw better insights from the data.
Unlike most other ways of looking at data, graphs are designed to express relatedness. Graph databases uncover patterns that are difficult to detect using traditional representations such as relational databases.
An increasing number of companies use graph databases to solve a variety of connected data problems, including fraud detection.
Semantic Search
Keyword-based search tools are a nightmare for enterprises! Why? Because a vast majority of organizational information is stored in an unstructured format and, keyword-based search tools do not comprehend unstructured data.
Bad search results frustrate employees and decrease working efficiency. And, in highly competitive markets, you can’t afford to miss out on leveraging the valuable data insights that drive your business growth! That’s why enterprises are turning into deploying semantic search tools.
How does Semantic Search work?
Semantic search is search with meaning, as opposed to “normal” search where the search engine looks for literal matches of the queried words without understanding the overall meaning of the query.
Semantic search takes into account the context of search, location and the intent of queries. It understands the searcher’s intent and the contextual meaning of terms in the Web, or on an enterprise data storage, and provides more relevant results.
Natural language can be ambiguous, but semantic search exposes the meaning behind the words. Rather than using ranking algorithms to predict relevancy, semantic search uses meanings to produce highly relevant search results.
It provides your organization with fast, relevant answers to complex questions based on user data and metadata, and other information about your business domain.
Network management for Telecom, IT, Power grids & Sewers
If you are familiar with network management in telecommunications, power grids, or IT, you probably know how complex it can be.
The complexity accumulates in networks over time – different business units are not aligned; companies grow through mergers and acquisitions, systems of different vendors are not communicating, and so on. Separate silos, layers, and domains are created, and each has its own relational database to store the network information.
If you want to aggregate all the siloed data into a central location to create a unified management view across the whole network, you must link multiple relational databases together, and by far the easiest way to do that is a Graph database. Shortly, you will be able to visualize bottlenecks and other issues in your network.
Graph Databases for networks
Graph databases are a perfect fit for modeling, storing and querying network and IT operational data. Networks are essentially graphs linked together.
As with master data, a graph database is used to bring together information from disparate management systems and data inventories, providing a single view of the network and the users – from the smallest network element all the way to the applications, services and the users.
A graph representation of a network enables managers to catalog assets, visualize their deployment and identify the dependencies between the nodes.
Graphs help in ensuring end-to-end redundancy on a network – you can see that if a network element becomes unavailable, or is taken down for maintenance, are there alternative routes available, and are the services and customers impacted.
Graph databases store configuration information to alert administrators in real-time about potential failures, and reduce the time needed for problem analysis and resolution.
Situational Awareness
Situational Awareness allows you to monitor environmental elements and events in real-time such as the weather or traffic with respect to time or space, understand their meaning, and project their status in the future to make smarter business decisions.
For example, a logistics company can monitor the weather and traffic, plot the situation a map, and proactively manage their fleet based on real-time data.
Situational Awareness analysis requires you to track a vast amount of data points describing the situation – temperature, humidity, probability of rain, and many other details, and their relation to the desired outcome to determine the best possible business decisions.
The technology of situation awareness
Situation Awareness consists of advanced semantic technology-based tools for modeling even the most complex business domains. These advanced tools are optimized for modeling business domains, query-based analysis of business domain data and several sophisticated visualizations for better business context and situation awareness.
Sense Situation Awareness includes leading GIS features and technologies like geosemantic queries, GML, WFS, WFS-T, GPS positioning, and SIM tracking.
